我用 AI 翻译的三个阶段:提示词时代 → 推理模型时代 → Agent 时代
宝玉
我做 AI 翻译这件事,前前后后折腾了快两年。从最早手写提示词,到现在用 Agent 自动分块、并行翻译、审校润色,中间踩了不少坑,也攒了不少经验。最近把这些经验整理成了一个可复用的翻译 Skill,这篇文章聊聊这个 Skill 是怎么一步步迭代出来的。
翻译这个场景比看上去复杂。提示词本身很简单,“把这段话翻译成中文”谁都会写。但要做成一个通用的 Skill,你得考虑:输入千奇百怪,有人贴一句话,有人丢一篇万字长文,还有人给个 Markdown 文件;每个人常用的语言对不一样;有时候只想快速看个大意,有时候要求翻译质量必须高。
太长的内容模型处理不了或者效果变差,需要分块,分块了又不好保证前后一致。这些问题不是一次想清楚的,是一轮轮迭代踩出来的。
我用 AI 翻译的三个阶段
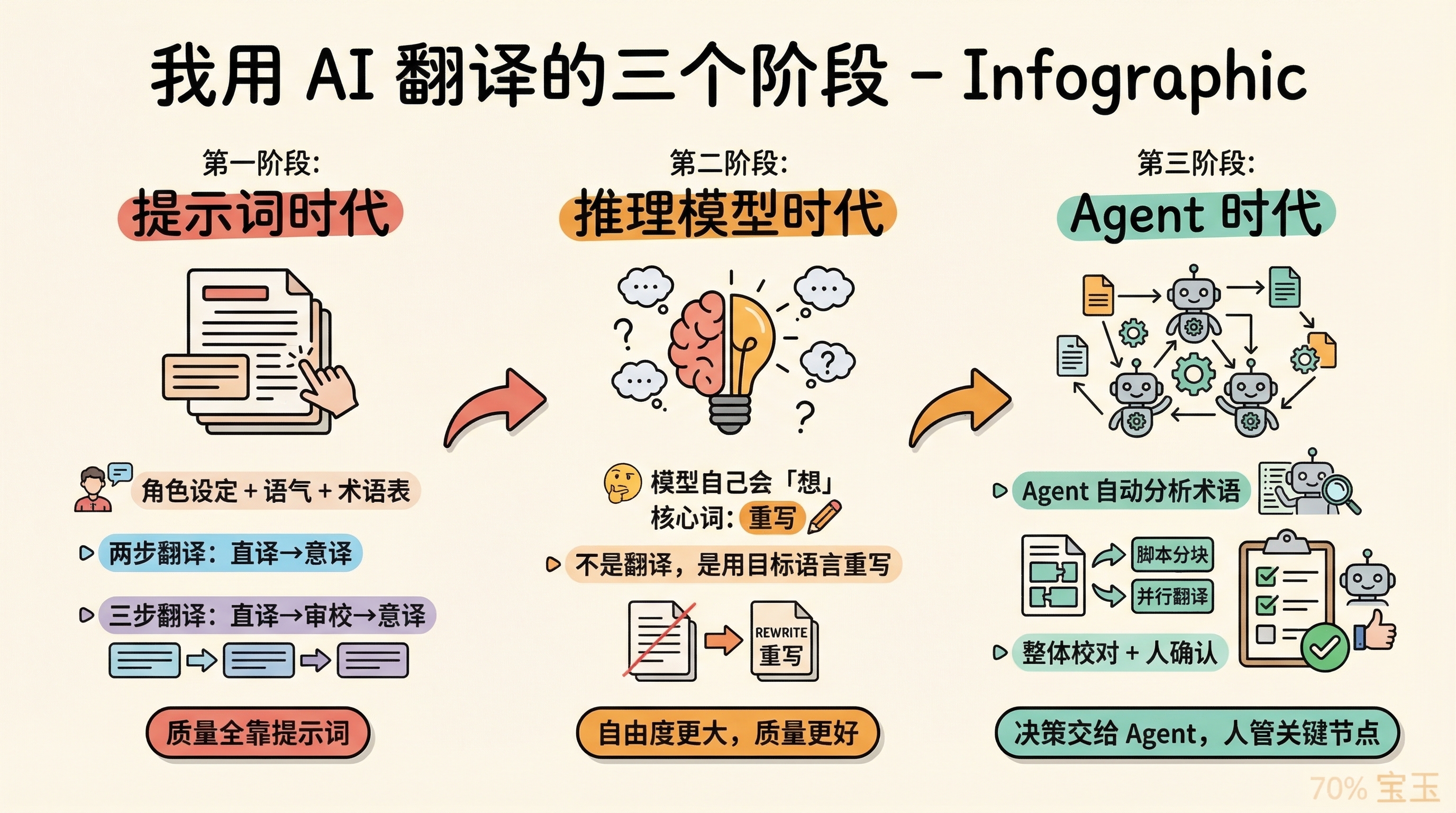
第一个阶段是推理模型出来之前。
那时候翻译质量全靠提示词,角色设定、语气要求、术语表,能塞的都塞进去。我应该是最早公开提出用“两步翻译”和“三步翻译”来提升翻译质量的。
两步翻译就是先直译再意译,原理类似推理链,让模型先老老实实把原文意思对上,再用更自然的方式重新表达。效果确实好,但费 Token。三步翻译多了一个中间的审校环节,先直译,再审校找问题,最后意译,效果更好,但上下文占用很大。
第二个阶段是推理模型出来之后。
有了推理能力,不需要我手动设计推理链了,模型自己会“想”。这时候翻译提示词的核心变成了一个词:“重写”。不是让模型“翻译”,而是让它用目标语言“重写”这段内容。“翻译”这个词会让模型惦记着原文的每个字,“重写”给了它更大的自由度去处理隐喻、重组句式。这个思路转变带来的质量提升很明显。
第三个阶段是 Agent。
到了 Agent 时代,翻译工作流可以做得更精细。之前所有决策都是我做的:要不要分块、分多大、用什么术语表、翻译质量够不够好。现在很多决策可以交给 Agent,但关键节点由人来确认。
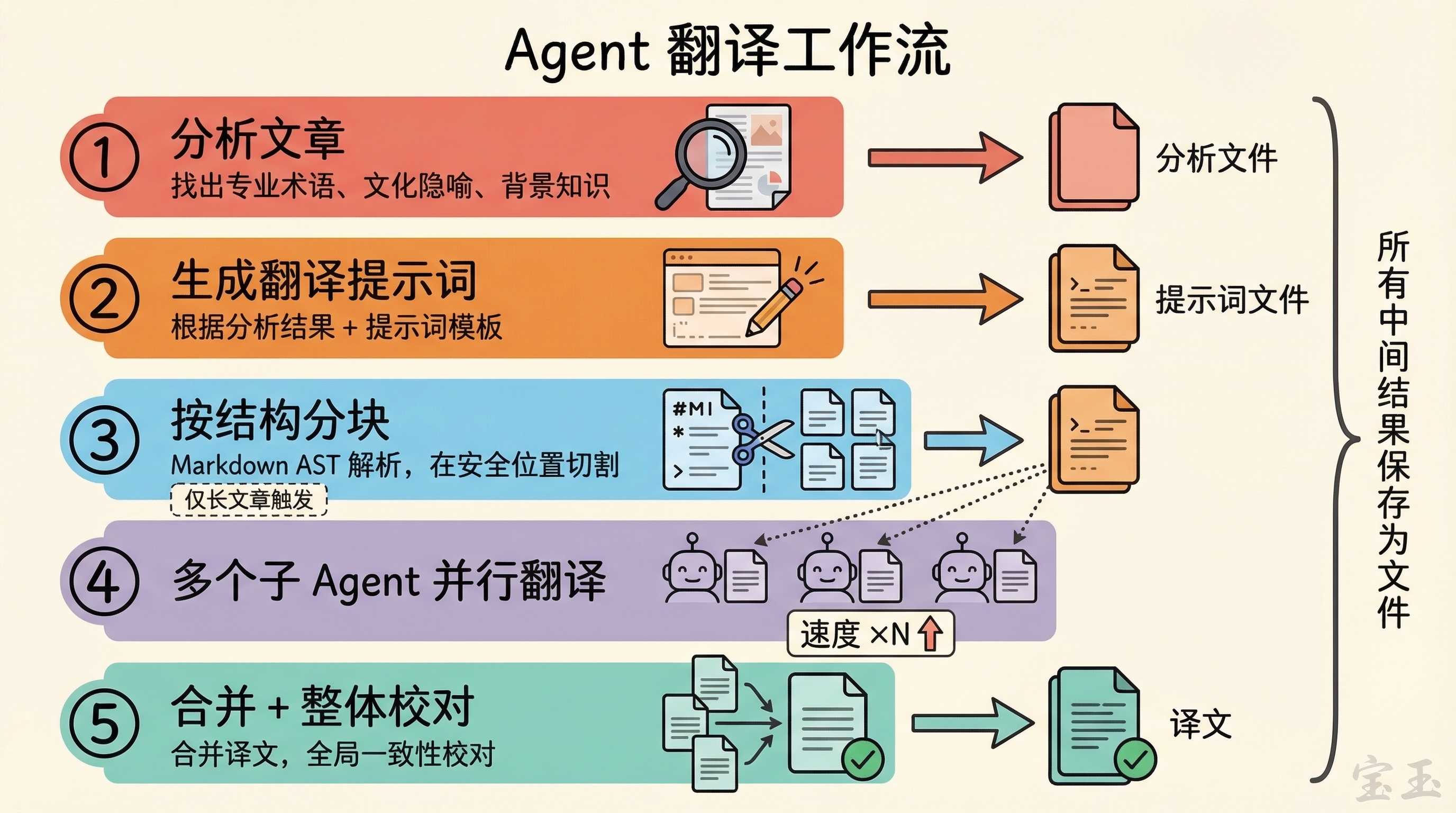
具体来说,我的 Agent 翻译工作流是这样的:
- Agent 先分析要翻译的文章,找出专业术语、文化隐喻、读者可能不理解的背景知识,保存成分析文件
- 根据分析结果和提示词模板,生成翻译提示词,也保存成文件
- 如果文章太长,用脚本按 Markdown 结构分块
- 多个子 Agent 并行翻译,每个负责一块
- 翻译完合并,再做整体校对
所有中间结果,分析报告、翻译提示词、每个分块的原文和译文、审校意见,全部保存成文件。翻译是个迭代过程,某一块翻得不好可以单独重翻,不用从头来。提示词有问题可以直接改文件,不用重新跑分析。
到了这个阶段,自然就想把整套流程做成 Skill 方便重用。
Agent 翻译和提示词翻译有什么不同
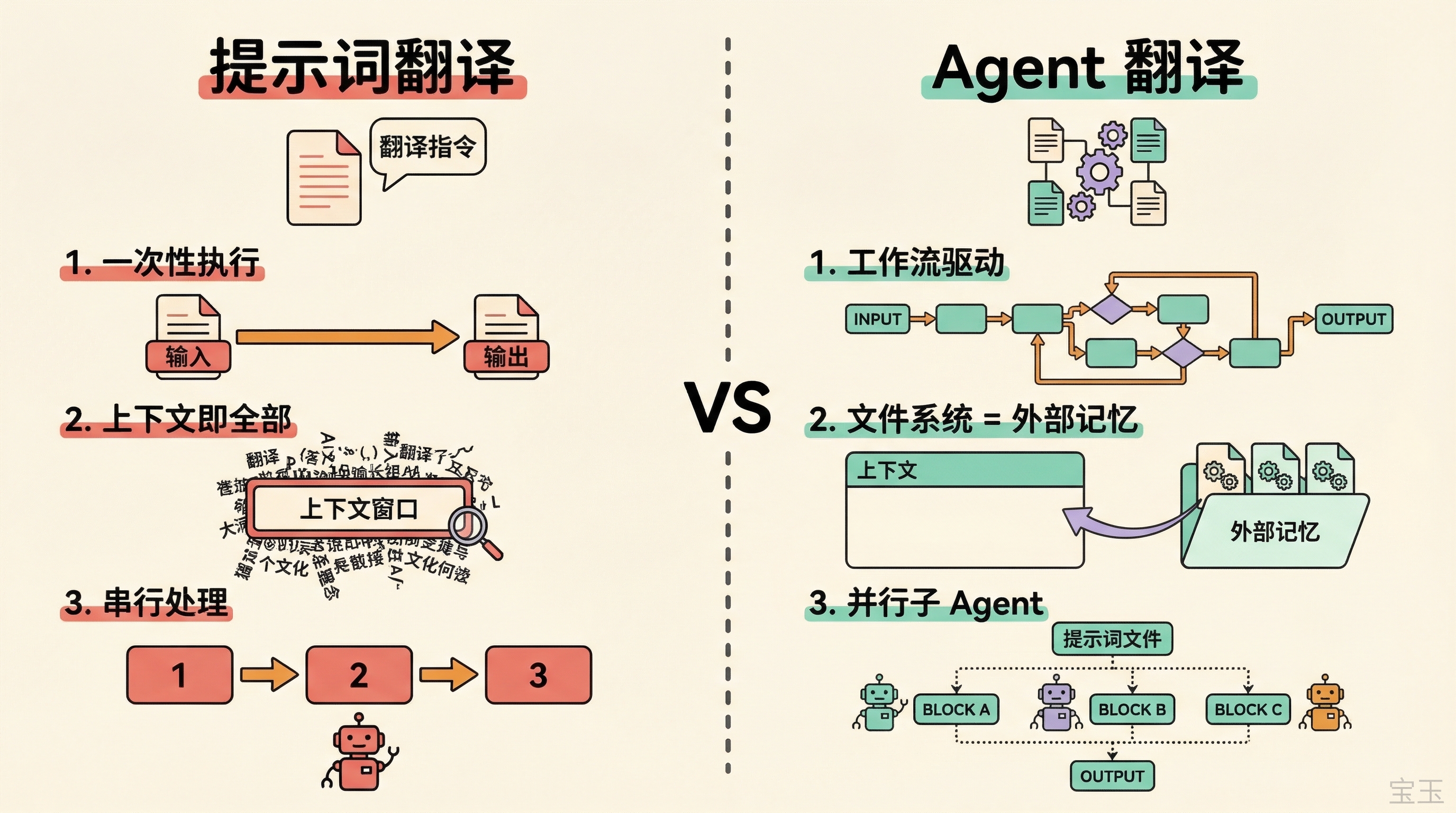
用提示词翻译,你把原文、指令、术语表塞进上下文,模型执行一次,输出就是结果。上下文窗口是你的全部工作空间,所有东西都得挤在里面。文章一长,要么截断要么硬塞,质量和成本都不好控制。
Agent 翻译不一样,差别在三个地方。
第一,Agent 有工作流,不是一次性执行。 它会按 Skill 设计的流程走,但不是死板地按步骤走。碰到短文章跳过分块,碰到长文章自己分析 Markdown 结构找安全的切分点,碰到纯文本和 Markdown 用不同的分块策略。目标语言、翻译风格、质量要求,都可以根据用户需求灵活调整。遇到问题它会自己写脚本来处理,比如写一段代码做 AST 解析,避免把表格或代码块切断。这些靠一条提示词做不到。
第二,Agent 能用文件系统当外部记忆。 分析结果存成文件,翻译提示词存成文件,每一块的译文也存成文件。Agent 不需要把所有东西都装在上下文里,需要什么读什么,上下文始终保持干净。传统提示词翻译,上下文就是你的全部,用完即弃;Agent 翻译,文件系统才是主记忆,上下文只是工作台。
第三,Agent 可以启动子 Agent 并行工作。 传统提示词翻译,一个模型从头翻到尾。Agent 可以起十个子 Agent,每个只拿共享的提示词文件加自己负责的那一块,独立翻译。速度提升好几倍,每个子 Agent 的上下文负载还更低,因为它只需要关注自己的那一块。
这三个能力组合在一起,让翻译从”写一条好提示词”变成了”设计一套翻译系统”。后面的内容就是这套系统怎么一步步迭代出来的。
Skill 怎么创建和迭代
创建 Skill 的过程本身不复杂。在 Claude Code 里用 skill-creator,把想法说清楚,它就能生成一个初步版本。
我的第一条指令就把核心需求说清楚了:
帮我为当前项目创建一个新的翻译的 skill:
- 两种模式:正常翻译,和精细翻译
- 有一个 EXTEND.md 可以定制默认的 target 语言、语言到语言的术语表等
- 如果是普通翻译,直接翻译即可
- 如果是精细翻译,做成一个工作流:先分析文章内容→初步翻译→review→润色等
- 如果是内容太长,需要分块翻译,但是要先把术语、人名先找出来,确保全文一致
同时我直接附上了参考翻译提示词和术语表样例,这样 Claude 不需要猜测我的翻译风格偏好。
整个 Skill 的创建和迭代过程是这样的:
- 在 Claude Code 里用 skill-creator,直接把想法说出来,生成初始版本
- 用生成的版本去翻译真实文章,不是测试用例,是真的要用的内容
- 读翻译结果,找出不满意的地方
- 把问题反馈给 Claude Code,让它改进 Skill
- 再翻译,再检查,循环往复
这个过程中,人的角色是质量判官和方向指挥。你要能判断翻译好不好,要能说清楚哪里不好,但不需要自己去写提示词细节。比如我发现串行翻译太慢,直接告诉 Agent“改成并行”,它自己去处理并行带来的一致性问题。再比如隐喻翻译生硬,我给它两版翻译让它自己总结规律,它总结出来的规则比我写的更系统。
三种翻译模式的由来
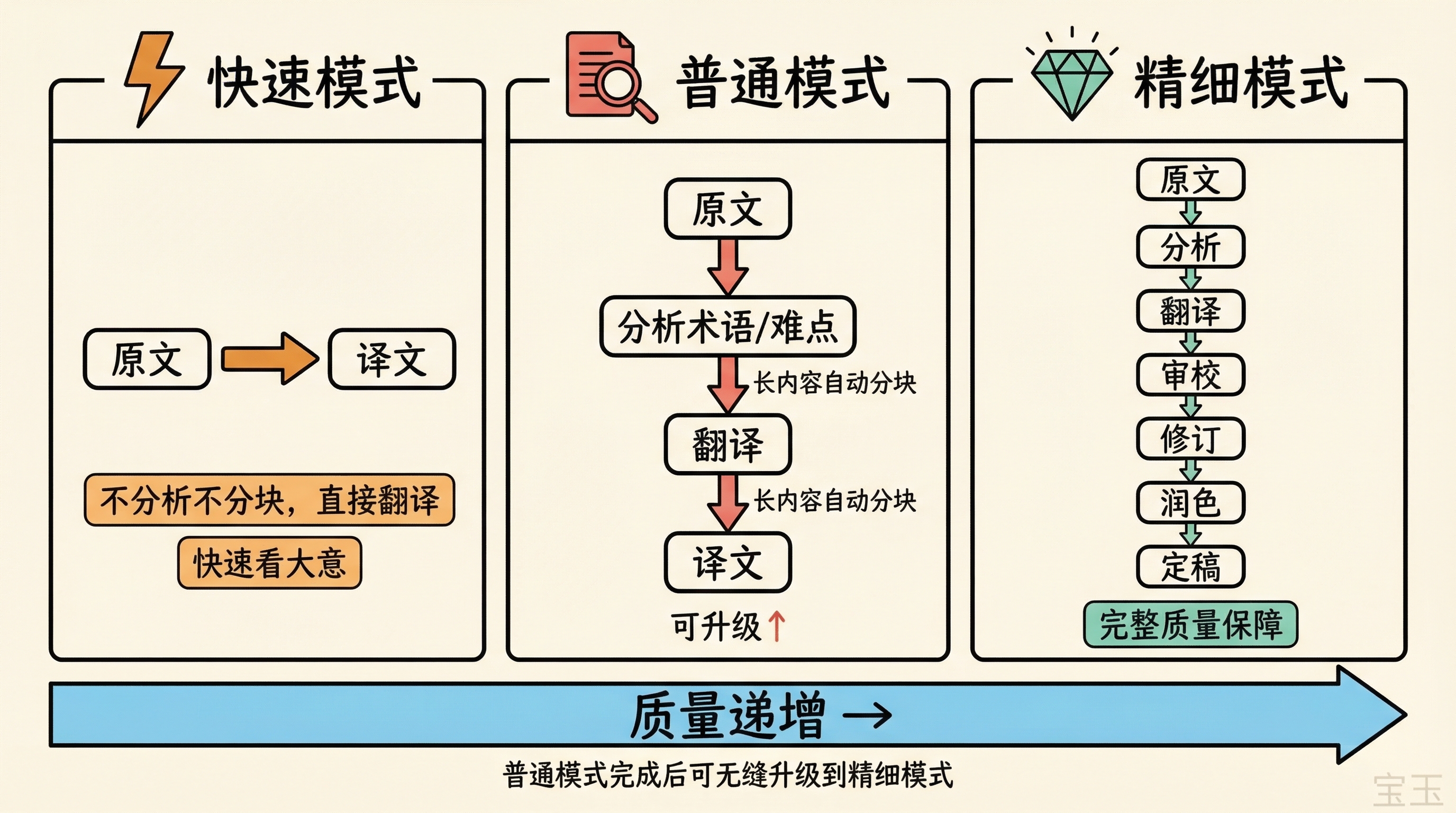
最初只设计了两种模式:普通和精细。后来发现很多时候只是想快速看个大意,普通模式的分析步骤多余了,于是加了快速模式,变成三种:
- 快速模式——不分析不分块,直接翻译,适合只想快速看个大意
- 普通模式——先分析文章内容,提取术语、识别难点,再翻译。长内容会自动分块,翻译完合并。结束后会问你一句:要不要继续润色?
- 精细模式——前面和普通模式一样,但后面会继续审校翻译结果,根据审校意见修订,最后润色定稿
这里有个用户体验的考虑:默认是普通模式。你不需要提前判断自己需要什么级别的翻译质量。大多数时候普通模式就够了,看完觉得需要更好,回复”继续润色”就能无缝升级到精细模式。所有中间结果都保存成文件,升级模式时不用重跑前面的步骤。
从串行到并行,解决一致性问题
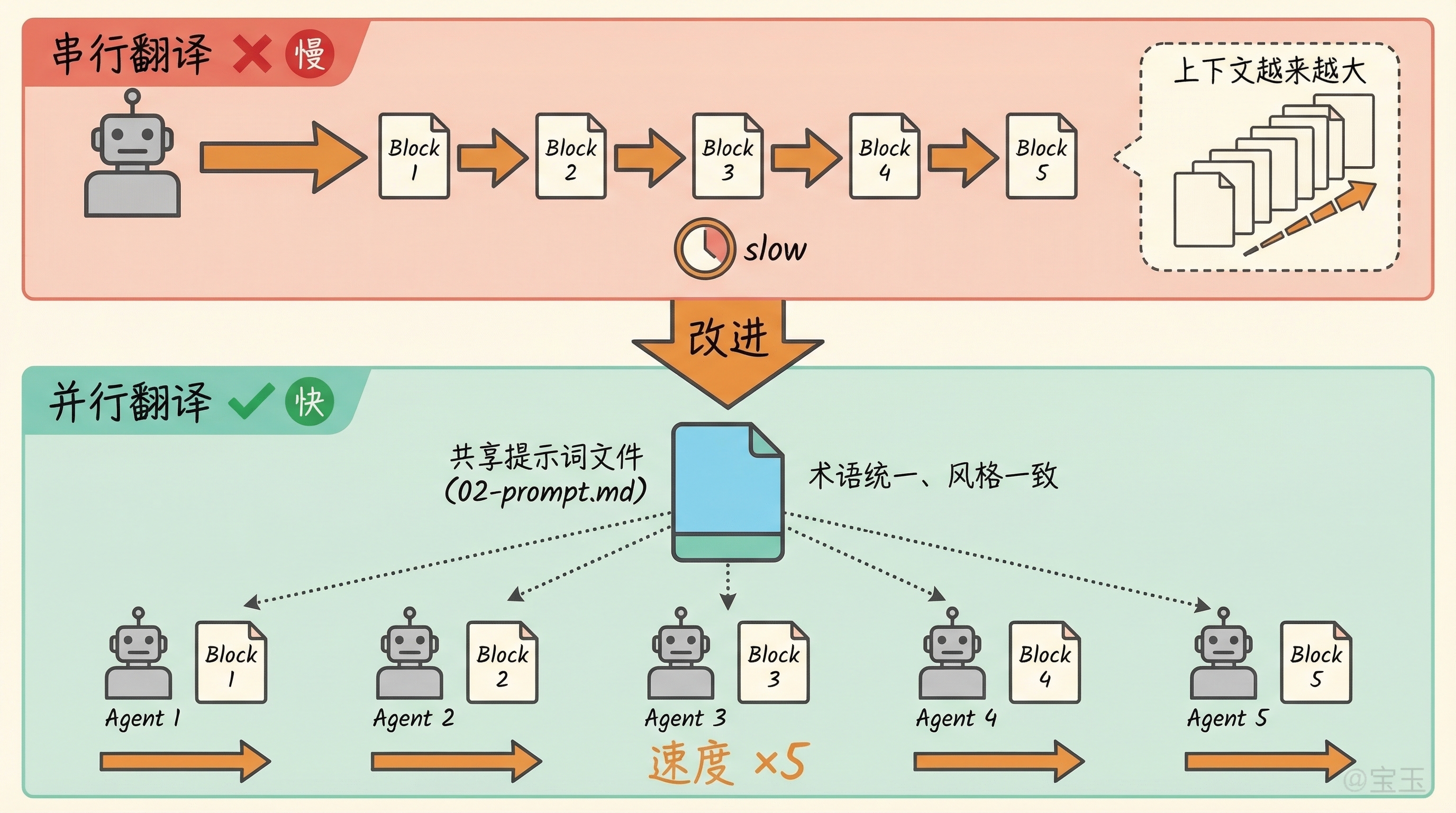
最初分块翻译是串行的。一个子 Agent 按顺序翻译所有块,上一块的结果放到下一块的上下文里,保证前后连贯。
但速度太慢,十个块要一个接一个翻译。更麻烦的是上下文可能会爆,如果截断之前的内容又没法用 Prompt Cache,成本反而更高。
改成并行呢?多个子 Agent 同时翻译不同的块,速度快了,但一致性没法保证。同一个术语,第一个子 Agent 翻译成“护城河”,第三个可能翻译成“竞争壁垒”。
解决方案是把一致性的保障从“运行时上下文”转移到“预先分析”。翻译之前先做一次内容分析,把术语表、翻译风格、命名约定都确定下来,写成一份分析报告。然后根据分析报告和提示词模板,生成一份完整的翻译提示词。
每个子 Agent 拿到的是同一份提示词加上各自负责的分块内容,术语怎么翻、风格什么调性,全部统一。十个块、十个子 Agent 并行执行,速度提升好几倍,一致性靠共享的提示词文件保证。
分块本身也有讲究。最开始按空行分段,会把表格、代码块、列表切断,后续处理很麻烦。后来改成用库做 Markdown AST 解析,只在结构安全的地方切割,比如段落边界、标题之后。
提示词传递的四次重构
这部分是迭代次数最多的。
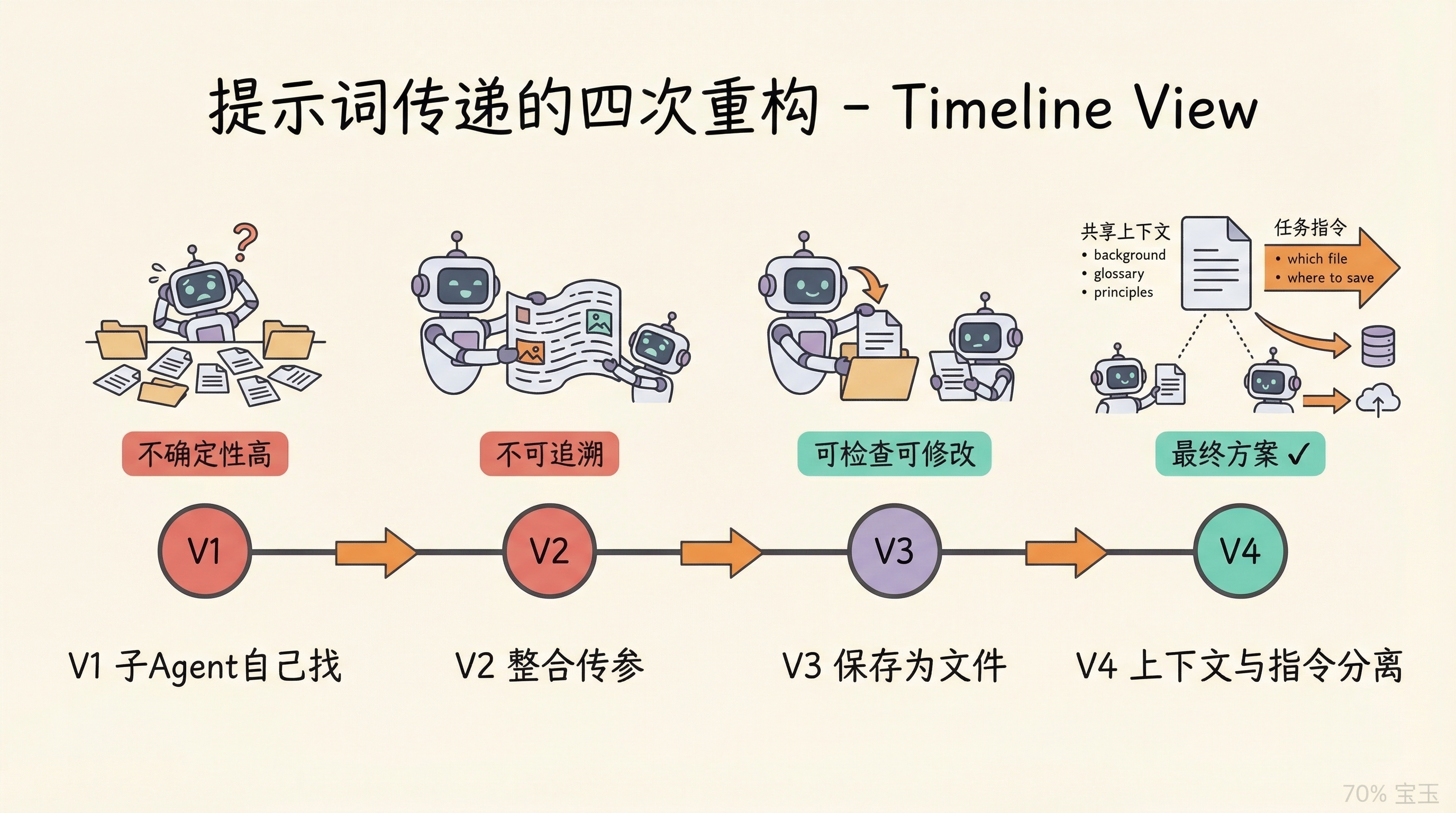
第一版,让子 Agent 自己去读分析文件。子 Agent 还得自己找文件、理解分析结果,增加了不确定性。
第二版,主 Agent 读取分析文件后,把所有上下文整合成一个完整的提示词,直接传给子 Agent。好了一些,但提示词只存在于调用参数里,没法追溯、没法手动检查。
第三版,把组装好的提示词保存成文件。子 Agent 读这个文件就行。提示词本身成了一个可追溯的中间产物,你可以打开看看生成的提示词对不对,甚至手动改。
第四版,实际测试时发现一个问题:提示词文件里包含了分块列表,子 Agent 看到所有块的信息会混淆,因为它只负责翻译一个块。于是把提示词拆成两部分,共享上下文(背景、术语表、翻译原则)保存为文件,任务指令(翻译哪个文件、保存到哪里)作为调用参数单独传入。
所有产物都保存成文件
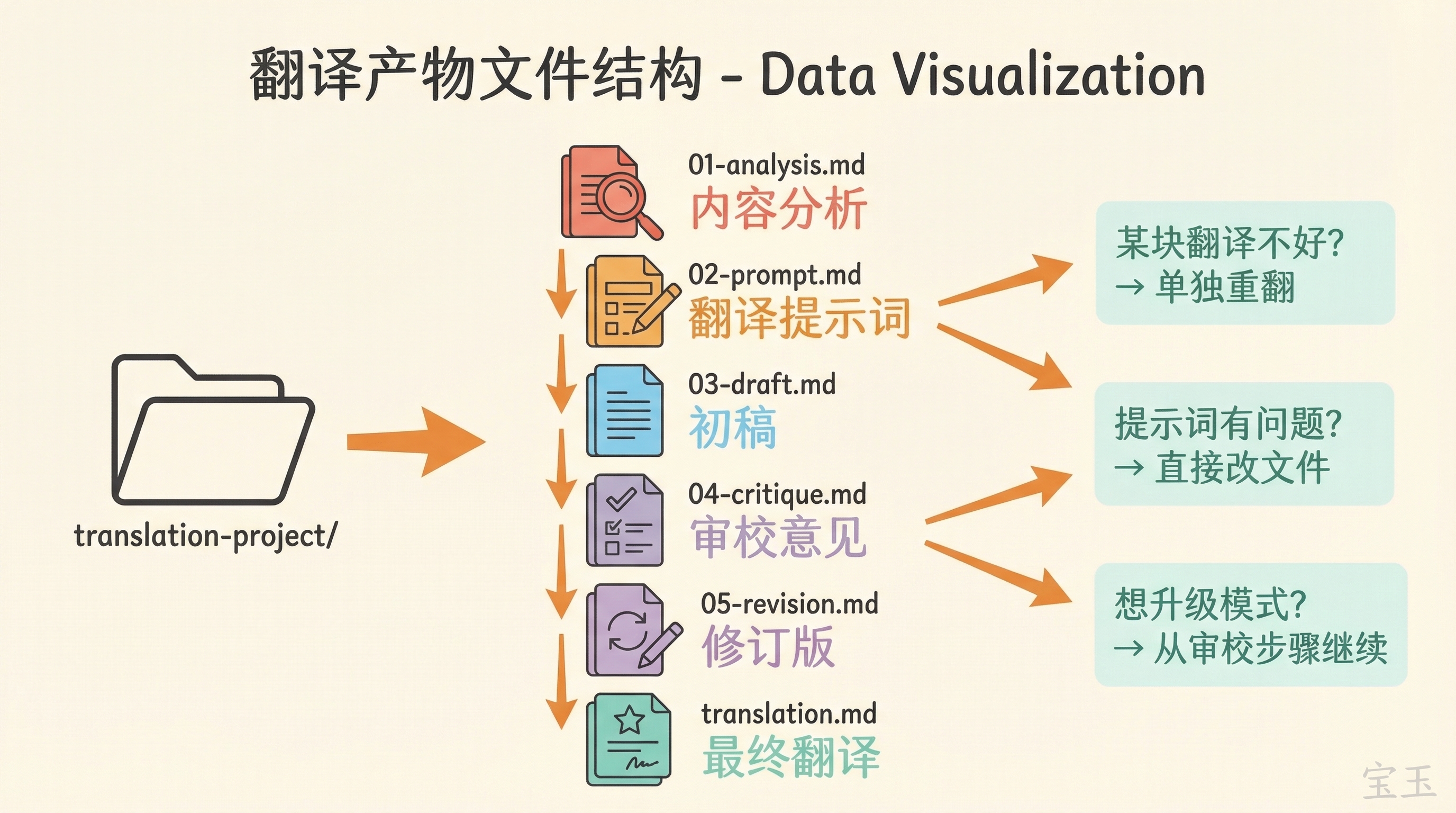
无论输入是文件、URL 还是粘贴的文本,第一步都是保存成文件。然后分析报告、翻译提示词、初稿、审校意见、修订版、最终翻译,全部保存在同一个目录里,用数字前缀标识步骤顺序:
01-analysis.md—— 内容分析02-prompt.md—— 翻译提示词03-draft.md—— 初稿04-critique.md—— 审校意见05-revision.md—— 修订版translation.md—— 最终翻译
某个块翻译质量不好?单独重翻那一块。想看看分析报告有没有遗漏?直接打开 01-analysis.md。想手动调整翻译提示词?改 02-prompt.md 就行。普通模式翻译完想升级到精细模式?前面的文件都在,直接从审校步骤开始。
并行翻译也因此可行,提示词已经是文件了,多个子 Agent 共享同一个文件,天然一致。
让 Agent 自己发现问题
翻译测试中发现一个典型问题。原文是:
“The Swiss had been watching the Japanese in the rear view mirror all through the 1960s, and they'd been improving at an alarming rate.”
模型翻译成了:
“整个 1960 年代,瑞士人一直从后视镜里看着日本人以惊人的速度追赶上来。”
而我期望的翻译是:
“整个六十年代,瑞士人一直把日本人看作身后的追赶者,而且对方进步的速度已经让他们感到不安。”
“从后视镜里看”是英文隐喻的直译,中文读者读起来别扭。“alarming”被翻译成“惊人的”,丢失了原文中瑞士人感到不安的主观情绪。
我的做法不是自己去改提示词。我手动整理了一份高质量翻译版本,然后让 Agent 自己去比较两版翻译,分析哪里好、怎么才能翻译得更好。
Agent 分析出了几个核心模式:隐喻要解读意图而不是直译字面意象;传达作者的意思而不是逐词翻译;保留用词的情感色彩,“alarming”不只是“惊人的”,还有“不安”的意味;用中文的强调结构而不是照搬英文语序。
然后 Agent 在三个层面做了优化。分析阶段新增了隐喻映射,要求对每个隐喻分析作者意图、直译风险、目标语言处理策略。翻译原则里加了“翻译意图不翻译字面”、“保留情感色彩”。审校阶段专门检查直译隐喻和情感扁平化问题。
整个过程我做的就是:发现问题、提供对比样例、指明方向。具体怎么改 Skill,让 Agent 自己来。
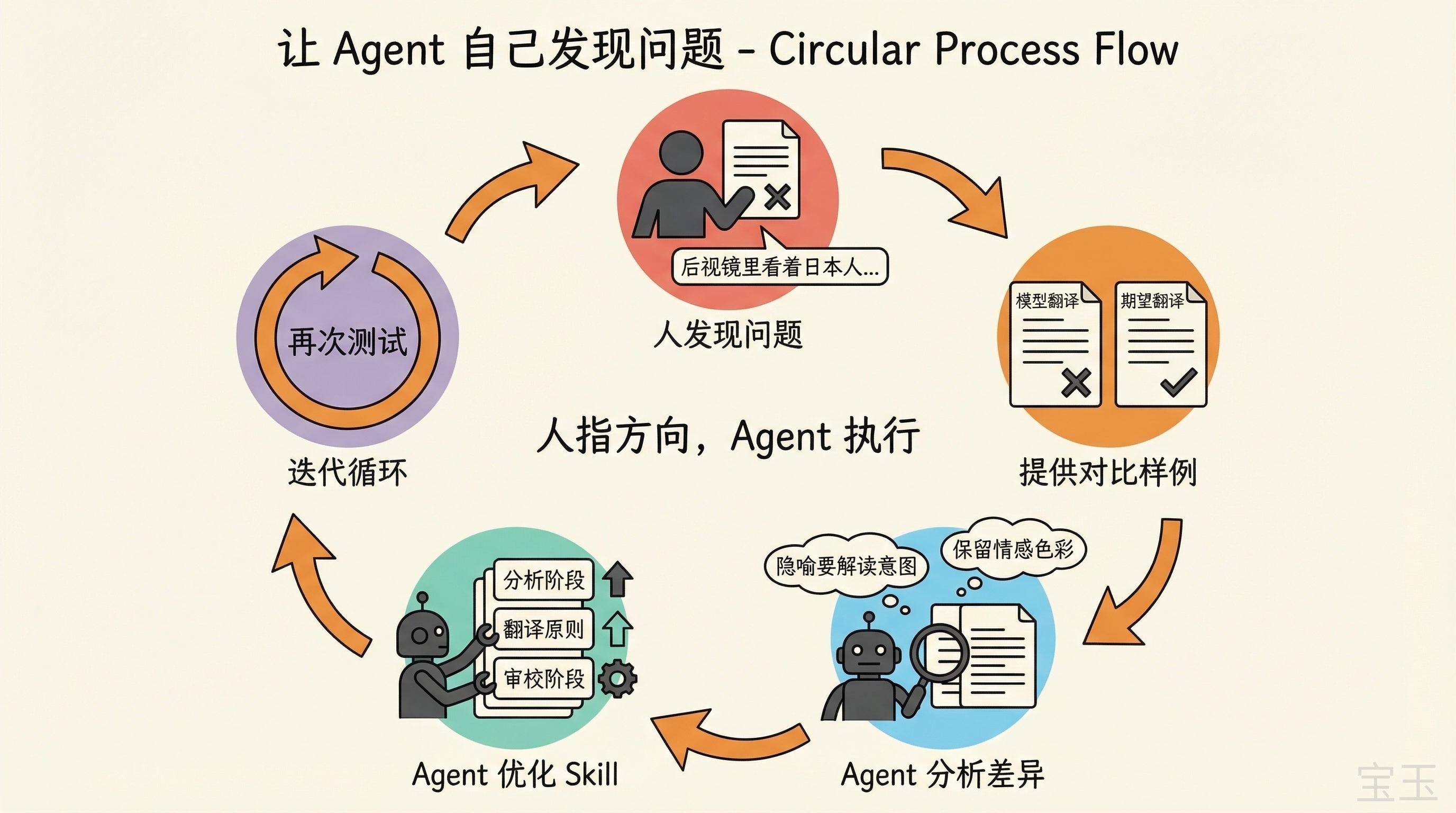
Agent 比你更懂怎么写好提示词,但你要告诉它方向。 你不需要去写 Skill 的具体规则,你需要做的是发现问题、提供好坏的标准,然后让 Agent 自己分析和优化。你测试,你指挥,它执行。
个性化设置
每个人翻译的需求不一样。有人主要翻英文到中文,有人翻日文到英文。有人面向技术读者,有人面向普通读者。
Skill 里设计了一个 EXTEND.md 文件,用户可以设置自己的默认目标语言、翻译风格、目标读者、术语表。第一次使用时会引导你做一次设置,之后每次翻译都会读取你的配置。
目标读者这个维度不只是一个配置项,它影响整个翻译策略。给普通读者要多加译注,给技术读者可以省略常见术语的解释。学术读者用正式语体,普通读者用叙事风格。
译注本身也有讲究。不是简单标个英文原词,而是用通俗语言解释含义。比如“遮秃效应”(comb-over effect,指一系列单独看来微小的变化,最终将你从略有偏差带入荒诞失常的境地),让不了解这个概念的读者也能顺畅读下去。
术语表的精简
一开始术语表有 60 多条,后来精简到 15 条。删掉了 Machine Learning 翻译成机器学习这类模型本身就知道的,只保留容易翻错或有争议的,比如 AI Wrapper 翻译成 AI 套壳、Hallucination 翻译成幻觉、Moat 翻译成护城河。
术语表是给模型的补充知识,不是全部知识。 模型知道的就别重复了,重复太多反而稀释了真正需要注意的条目。
类似的思路也用在了配置管理上。Skill 里有分块阈值、每块最大词数这些参数,最开始散落在各处,改一个要找好几个地方。后来统一放到一个 Defaults 表里,EXTEND.md 里的设置可以覆盖默认值,具体数字只出现一次。
回头看,几个反复出现的原则
第一,所有产物持久化。 源文件、分析、提示词、初稿、审校、终稿都保存为文件,可追溯、可调试、可恢复。
第二,关注点分离。 分析归分析,翻译归翻译,审校归审校。子 Agent 只负责初稿翻译,审校和润色需要全局视角,交回主 Agent。
第三,渐进式体验。 默认普通模式,完成后提示可以升级,用户不需要提前预判。
第四,并行优先。 在保证质量的前提下尽量并行,通过共享提示词文件让多个子 Agent 独立工作。
第五,提示词即代码。 翻译提示词保存成文件,可检查、可修改、可复用。
从“把这段话翻译成中文”到一个完整的翻译 Skill,这中间的距离比我预想的大。翻译提示词确实简单,但一个好用的翻译工具要处理的问题远不止翻译本身:输入格式、分块策略、术语一致性、质量分级、中间产物管理、个性化配置。这些问题没有一个能靠一条提示词解决,但也没有一个需要你自己从零写代码。你的价值在于判断质量好坏、发现问题、指明方向。具体怎么优化,让 Agent 来。
项目地址:https://github.com/JimLiu/baoyu-skills
安装方法:
npx skills add https://github.com/jimliu/baoyu-skills --skill baoyu-translate
小龙虾🦞和 Claude code 都可以用。